Perhaps the ordinary way to produce messages to the Kafka is through the standard Kafka clients. But if you want to just produce text messages to the Kafak, there are simpler ways.In this tutorial I ‘ll show you 3 ways of sending text messages to the Kafka.
kafka-console-producer
One way is through kafka-console-producer that is bundled with Kafka distribution. For example to send a file to the Kafka, you can write:
cat YOUR_TEXT_FILE | $KAFKA_HOME/bin/kafka-console-producer.sh --broker-list YOUR_KAFKA_BROKER:9092 --topic YOUR_TOPIC
That command reads the file line by line, and produces kafka record for each line.
Kafka Connect
Another way to send a file to the Kafka line by line is through Kafka Connect. The easiest way to use Kafka Connect is through Confluent Open Source or Confluent Enterprise. Download and install one of them. Start confluent:
$CONFLUENT_HOME/bin/confluent start
Then save this config file somewhere (For example /tmp/connect-source-file.properties) :
name=my-local-file-source
connector.class=FileStreamSource
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
tasks.max=1
file=YOUR_TEXT_FILE
topic=YOUR_TOPIC
Replace YOUR_TEXT_FILE with your file path and YOUR_TOPIC with your Kafka topic name.Then send file to the Kafka by:
$CONFLUENT_HOME/bin/confluent load my-local-file-source -d /tmp/connect-source-file.properties
Done! check your topic to ensure that it successfully published.
Filebeat
Another way to send text messages to the Kafka is through filebeat; a log data shipper for local files.
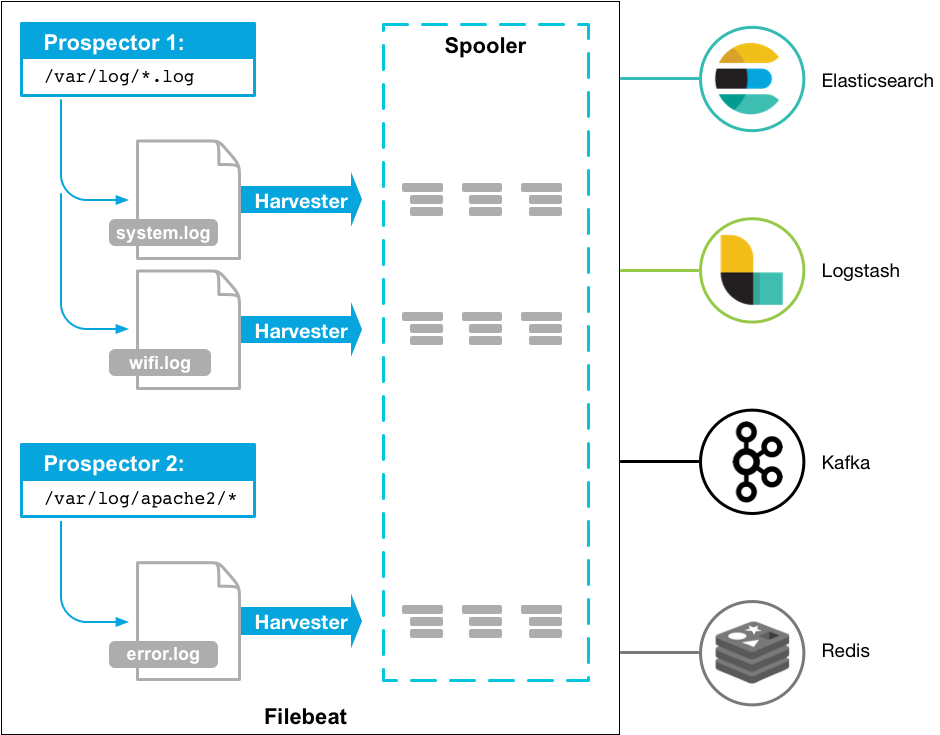
Here’s how Filebeat works: When you start Filebeat, it starts one or more prospectors that look in the local paths you’ve specified for log files. For each log file that the prospector locates, Filebeat starts a harvester. Each harvester reads a single log file for new content and sends the new log data to libbeat, which aggregates the events and sends the aggregated data to the output that you’ve configured for Filebeat.
First install filebeat. Then edit filebeat.yml as:
filebeat.prospectors:
- type: log
enabled: true
close_eof: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /tmp/logs/*
#- c:\programdata\elasticsearch\logs\*
output.kafka:
enabled: true
codec.format:
string: '%{[message]}'
hosts: ["localhost:9092"]
topic: 'tpk1'
version: '0.11.0.0'
partition.round_robin:
reachable_only: false
required_acks: -1
max_message_bytes: 1000000
Ensure that you change paths , hosts and topic correctly.
close_eof: true
I set close_eof because I wanted filebeat close the file handler whenever it reaches the end of file. Otherwise filebeat watches for the file change.
codec.format:
string: '%{[message]}'
I set above config to tell filebeat that send line messages as raw. Otherwise filebeat wrap your line in JSON. For
more information on configuration check Configuring filebeat
After you ‘ve done you can start filebeat :
./filbeat -e -d filebeat.yml
Apache Flume
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.At the high level, it consists of 3 main component:
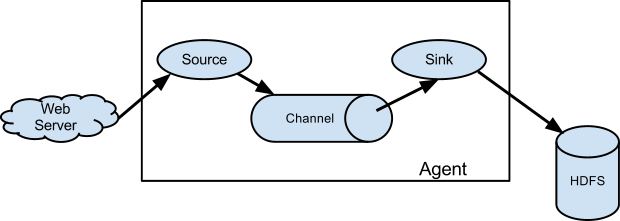
- Source
- Channel
- Sink
Flume Source consumes events from various sources and write them to the channel.The channel is a passive store that keeps the event until it’s consumed by a Flume sink.The sink removes the event from the channel and puts it into an external repository like Kafka or HDFS.
Download and extract Apache Flume.Create a flume config file somewhere (For example /tmp/flume-conf.properties)
agent1.sources = s1
agent1.channels = c1
agent1.sinks = k1
agent1.sources.s1.type = spooldir
agent1.sources.s1.spoolDir = /tmp/myLogs/
agent1.sources.s1.channels = c1
agent1.channels.c1.type = memory
agent1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.k1.kafka.bootstrap.servers = localhost:9092
agent1.sinks.k1.kafka.topic = tpk1
agent1.sinks.k1.channel = c1
In this config, Flume watches the specified directory for new files, and will parse events out of new files as they appear. The event parsing logic is pluggable. After a given file has been fully read into the channel, it is renamed to indicate completion (or optionally deleted).For more configuration check Spooling Directory Source
To start the flume agent, type :
./flume-ng agent -n agent1 -f=/tmp/flume-conf.properties
That’s it. :)